
사자성어에도 유유상종이라는 말이 있듯이, 서로 가깝게 위치하는 사물이나 생명체들의 특성이 서로 비슷하거나 일치하는 것은 우리주변에선 흔히 볼 수 있는 현상이다.
머신러닝도 이런 특성을 가진 분류 알고리즘을 가지고 있는데, 그것이 바로 K-nn이다.
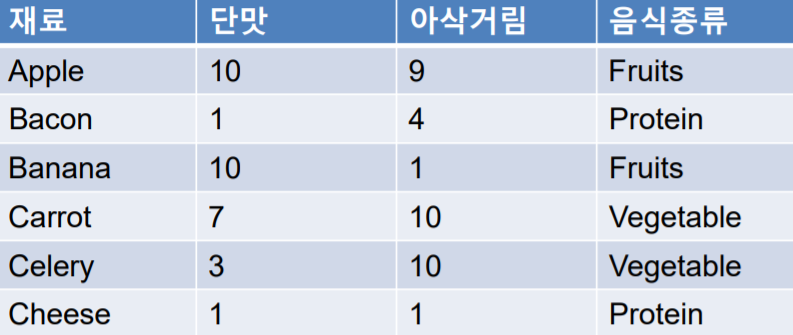

예를 들어 그림 1과 같이 단맛과 아삭거림, 이 두 가지 척도(변수)에 따라 음식종류를 분류(Classification)할 수 있다고 하자. 그림 1의 표를 그림 2의 2차원 그래프로 옮겨보면 위와 같을 것이다. x축은 단맛, y축은 아삭거림으로 설정한 것이다.
그림 2야 말로 정말 유유상종이 아닌가? 아삭거림에 상관없이 단맛이 높게 나타난 그룹은 과일그룹, 단맛에 상관없이 아삭거림이 높게 나타난 그룹은 채소그룹, 그리고 단맛과 아삭거림 모두 다 낮게 나타난 그룹은 단백질 그룹에 속한다.
물론 이 그룹을 만드는 망의 크기를 정하는 것은 좀더 수학적인 거리계산을 고려해야 정확하겠지만, 일단 필자로써는 그림 2도 눈대중으로 보았을 때는 나름 합리적인 퀄리티라고 생각한다.
만약 위의 분류에 따른 데이터 셋(Training data)에 새로운 식재료가 들어가면 어떻게 분류할 것인가? 이것이 바로 이번장에서 다루고자하는 기법이다. nearest neighbor 라는 이름처럼 분류되지 않은 새 데이터는 가장 가까운 식재료를 찾기 마련이다. 이때 몇 개의 가까운 이웃을 선정하여 분류(y)할 것인가에 초점을 두게 되면 비로소 k-nn을 이용하게 된 것 이다. (k개의 nearest neighbor)
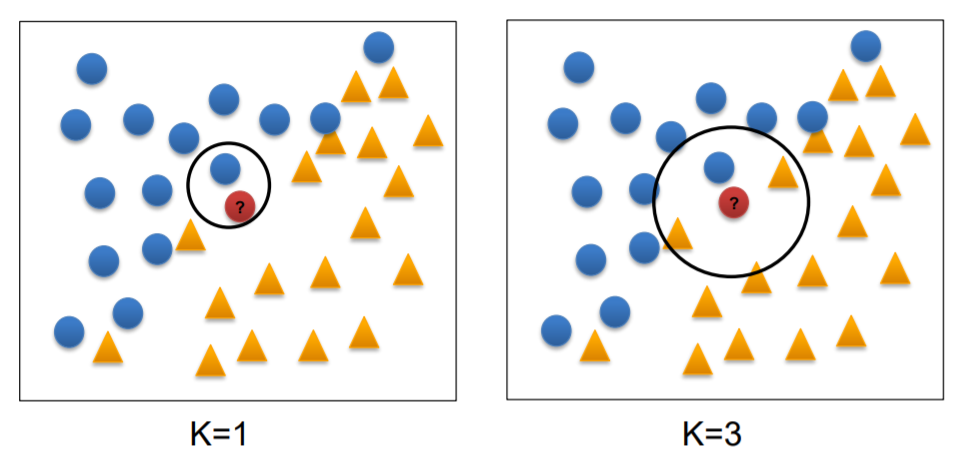
그렇다면 k는 어떻게 선택될까? 그림3처럼 k값에 따라 분류가 다르게 될 수도 있다는 것을 알 수 있다. 하지만 위의 사진에서는 잘 나뉘어진 두개의 군집에서 boundary에 해당하는 것들이기 때문에 k값에 특히 예민한 것도 눈치 챌만하다. 다르게 말하면, 구석이나 군집 중간에 있는 데이터들은 k값에 예민하지 않을 수도 있다는 말이다. 정리하자면, k값의 선택은 훈련데이터의 개수나 학습하는 개념의 난이도에 따라 다르다. 콕 집어 정하는 것은 아닌 유동적인 값이라고 이해하면 되겠다. (아주 일반적인 방법은 Training data의 개수의 제곱근으로 결정할 수도 있고, 가중치 투표도 있다)
결론적으로 이 k-nn을 배우는 최종 목적은, 어떤 특정한 데이터를 분류할 때, 최적의 k값을 찾아내는데에 있다고 봐도 무방하다. (*예외로 데이터에 특이점이 있거나, Training data 개수가 많다면 k값의 선택은 덜 중요한 문제가 될 것이다.)

k-nn은 분명 아주 단순한 Classification이다. 일반적인 머신러닝 기법과는 달리 모델을 생성하지 않기 때문이라고 할 수 있다. 모델을 생성하지 않기에 데이터 분산에 따른 추정치를 계산할 필요조차없다. 하지만 모델을 생성하는 것이 아니기에 새로운 데이터를 분류(find y)하려할때 다시 서로간의 거리를 계산하기 때문에 기계 입장에선 느린 분류라고도 볼 수 있다는게 단점이다. (함수로 모델링하면 바로바로 나오는데 반해) 그리고 카테고리(범주)형 변수는 factor로 바꿔주어야하고, missing data를 넣을건지 말건지에 대한 판단도 필요한 만큼 귀찮음도 존재한다.
*데이터 셋의 구성에 대해 잠깐 알아보도록 하자. 데이터 셋은 크게 Training data와 test data로 나뉜다. (Training data 안에 확인을 위한 validation data가 들어가기도 한다) 골자 그대로 모델링을 하기 위한 용도로 쓰이는 것이 Training data이고 새로운 데이터를 예측하는 용도로 쓰이는 것이 test data이다.

**k-nn은 거리를 기반으로한 기법이기 때문에, 데이터의 scale에 예민할 수 밖에 없다. 따라서 scale차이에 따른 영향력을 줄이기 위해 속성을 표준범위로 변환하는 작업을 거친다. z표준화는 익히 알던 익숙한 표준화이고, min-max 정규화 또한 0에서 1사이로 변환시키는 방식이다. (*극단적으로 속성이 min이면 0의 값을 가지고, max면 1의 값을 가짐)
**위에서 k-nn의 단점중, 명목형 변수의 변환이 있지 않았나? 그에 해당되는 또 하나의 사전작업을 설명하겠다. 명목형 (ex: 남,여) 데이터를 수치로 만들기 위해서는 더미 코딩을 해야한다 남자를 1, 여자를 0 처럼 말이다. 더미코딩은 이진지시변수로 만들어주는 것인데, 규칙을 일반화하자면, n개의 범주속성이 있을 때, 반드시 n-1 정도에 대한 더미코딩을 해줘야한다.

즉, 위와 같은 예시일 경우, 3개의 속성 중 하나의 속성에 대한 더미코딩은 필요없다는 이야기이다. 왜냐면 3개중 2개의 속성에 대한 더미코딩만으로도 나머지 하나의 속성을 표현할 수 있기 때문이다.

R로 위의 과정들을 이용해 데이터들을 정리하면, train 데이터의 x(속성), test 데이터의 x(속성), train 데이터의 y(class), 그리고 k를 이용해 우리가 결론적으로 알고 싶은 test 데이터의 class(y)를 예측할 수 있다. (train data의 class 는 R의 클래스 패키지를 이용)
*평가*

위의 크로스 테이블에서 행은 test data의 실제 class, 열에 속하는 것이 전전 그림의 test-predict이다. 여기서 오른쪽 사진의 용어를 써서 결과를 평가할 수 있다. ( ex: 열과 행이 만나는 것이 일치하면 True 즉, 맞았다는 뜻이고 뭘로 예측했느냐가 뒤에 붙는다. 예를 들면 TP면 맞았는데, Positive로 예측한 것이 되는 것이다.)
오른쪽 confusion matrix에서 세 가지 공식을 사용한다.
1.Precision( Y로 예측한것들 중에 실제로 Y인 것의 확률)
2.Recall(실제 Y인 것들 중에서 Y로 예측된 대상의 비율)
3.Accuracy(전체중에 올바르게 예측한 비율이며 정확성이다)
'데이터 마이닝 (머신 러닝)' 카테고리의 다른 글
| 중간비교: K-nn, Naive Bayes, Dicision Tree의 특징비교 (0) | 2021.04.05 |
|---|
Comment